Built for zero trust, designed for composability
MindooDB's architecture separates the sync concern (moving encrypted bytes) from the application concern (decrypting and interpreting data). This single design choice enables client-server, peer-to-peer, relay, and mesh topologies — all using the same protocol and the same code.
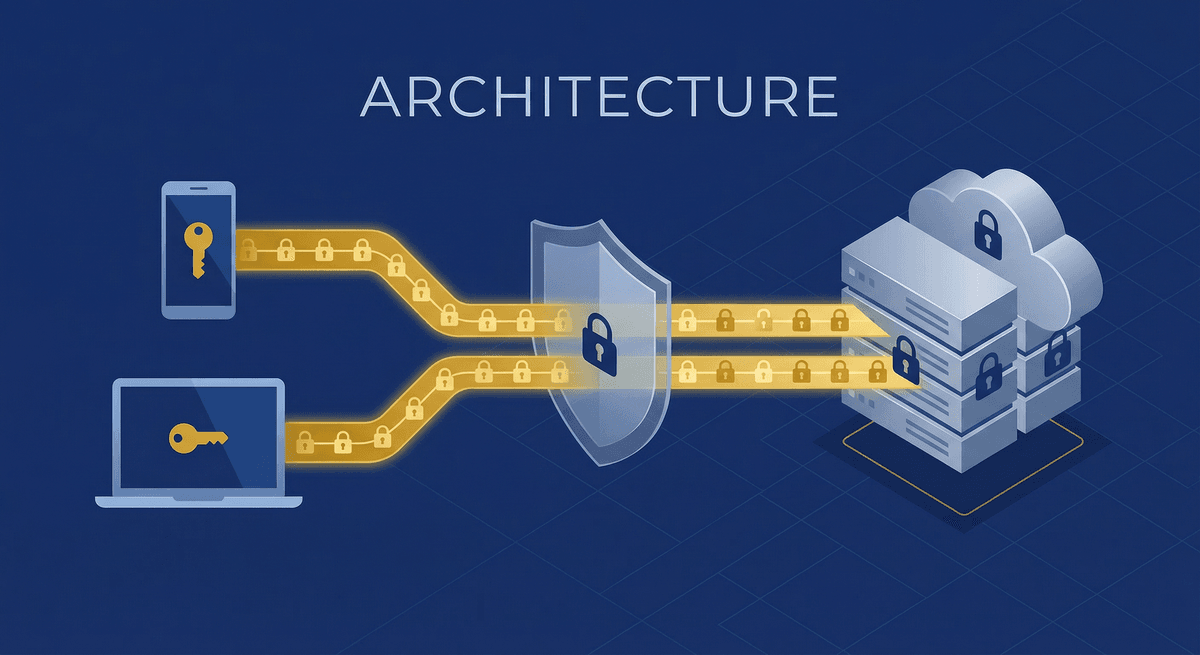
What this architecture gives you
If you are evaluating MindooDB for your team, the key architectural question is: can I adopt this incrementally without locking in? The answer is yes. MindooDB is designed for progressive adoption — start local-only, add client-server sync when ready, enable P2P or relay topologies later. Every step uses the same ContentAddressedStore interface, so changing your deployment model is a configuration decision, not a code rewrite.
Hours for local-only. Days for client-server sync (2 auth + 3 sync endpoints). Incremental for P2P, relay, or Bloom filter optimizations — no protocol changes needed.
Three independent protection layers: AES-256-GCM at rest, per-user RSA in transit, TLS on the wire. Servers never see plaintext. A full server breach yields only ciphertext and public keys.
No server-side user accounts, no password storage, no session databases. The server is a relay for encrypted blobs. User management happens client-side through cryptographic key pairs.
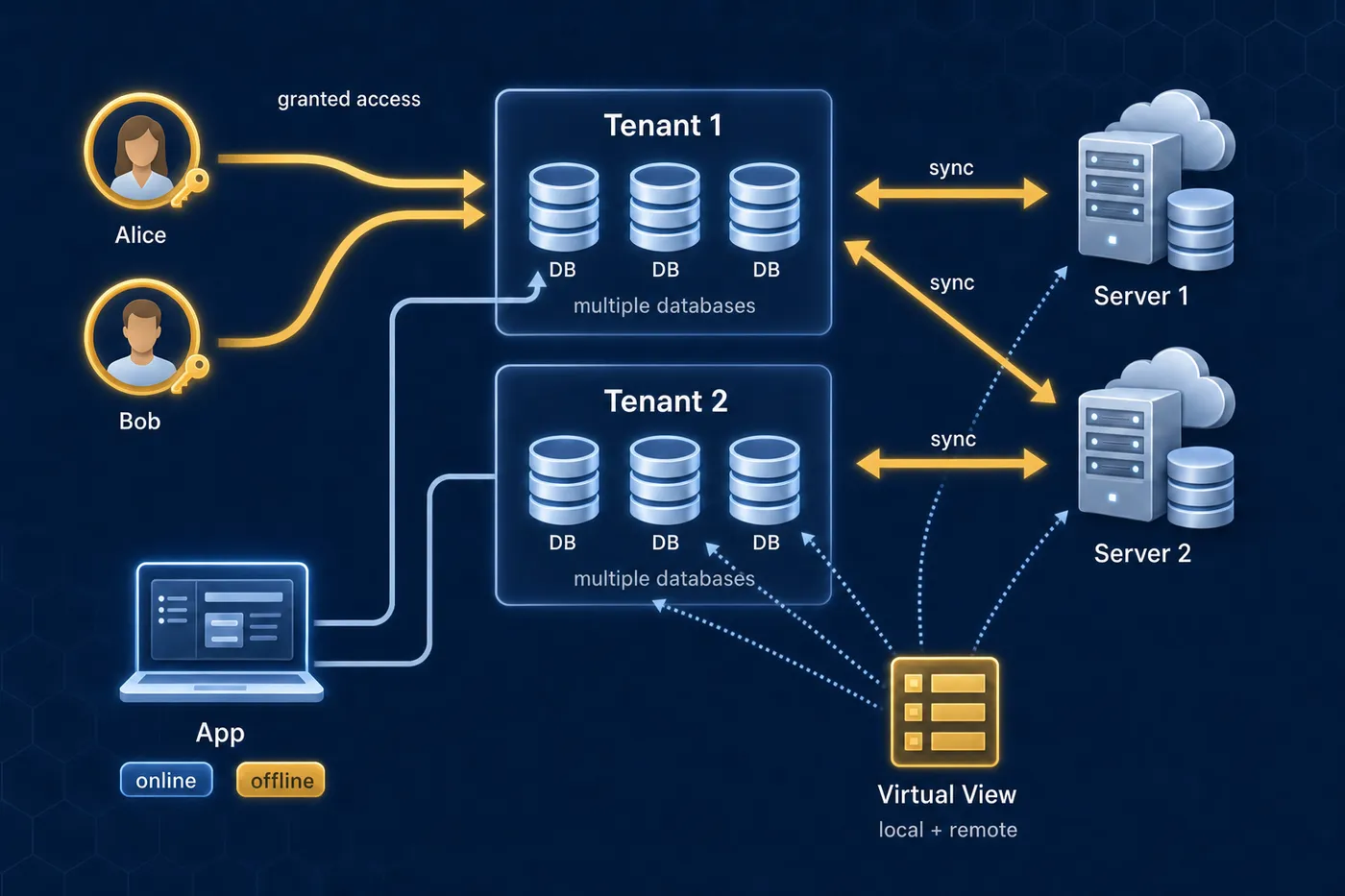
Tenants, users, and the trust chain
A MindooDB tenant represents an organization or team. Tenants are created entirely client-side — no server registration needed. The tenant creator becomes the administrator, whose Ed25519 signing key is the root of trust. Every user registration in the directory is signed with this admin key, and clients and servers verify these signatures before trusting any user's public key. This means trust is established through cryptographic proofs, not server authentication.
Each tenant contains a directory database (admin-only user registry), multiple application databases, and the keys that control access.
- Directory database — Admin-signed user registrations, group memberships, settings
- Application databases — Created on demand (
tenant.openDB("contacts")) - Documents — Automerge CRDTs with signed, encrypted, append-only history
- Attachments — Chunked (256KB), encrypted, deduplicated file storage
Trust flows from the admin key through the directory to registered users. Each key type serves a specific purpose:
- Admin signing key (Ed25519) — Root of trust; signs directory entries
- Admin encryption key (RSA-OAEP) — Encrypts usernames for privacy
- User signing keys (Ed25519) — Prove authorship of document changes
- User encryption keys (RSA-OAEP) — Protect local KeyBag storage
- Default tenant key (AES-256) — Encrypts documents for all members
- Named keys (AES-256) — Fine-grained access for specific users
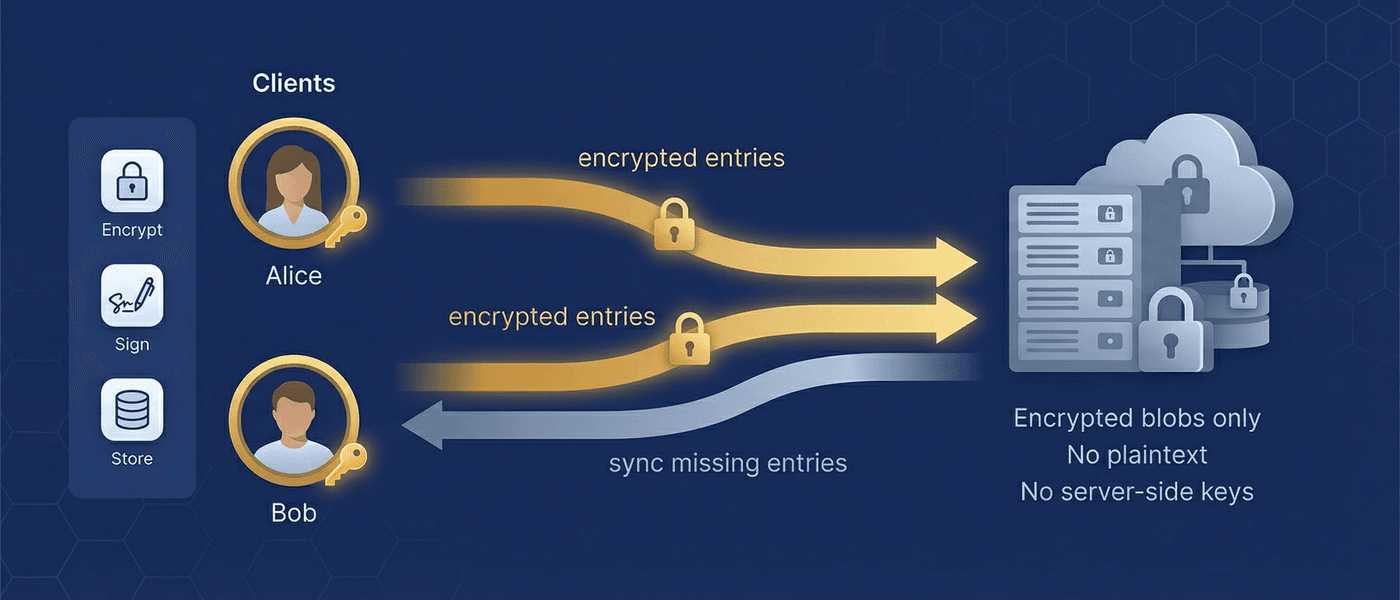
The content-addressed store
At the center of MindooDB's flexibility is the ContentAddressedStore interface. Every store — whether backed by local disk, in-memory data, or a remote network connection — implements this same interface. The sync methods pullChangesFrom() and pushChangesTo() accept any ContentAddressedStore, which means they work identically regardless of whether the other side is a local store, a remote server, or another client connected over WebRTC.
This is the design insight that makes every topology possible: by making network stores implement the same interface as local stores, sync becomes composable. A server's backing store can be another remote store (store chaining). A relay can forward encrypted entries without decrypting them. A peer can run the same sync logic as a server. The topology is a deployment decision, not a code change.
Every document change, snapshot, and attachment chunk is stored as an immutable entry with a unique ID and content hash. Entries are never modified or deleted — this guarantees a complete audit trail.
Each entry references its parent entries by ID (forming a DAG) and is signed by its creator. Tampering with any entry breaks the chain — integrity is verifiable at any point.
Entries are identified by id and deduplicated by contentHash (SHA-256 of encrypted payload). Identical content from multiple sources is stored once.

Start simple, optimize later
The sync protocol offers three paths that share the same endpoints and entry model. Baseline sync is the simplest: send your known entry IDs, receive metadata for what you're missing, fetch those entries. This works for any dataset size and is the recommended starting point. Optimized sync adds cursor-based scanning and Bloom filter summaries for larger datasets — these are negotiated at runtime through capability discovery, so they're transparent to application code. Dense sync uses the causal materialization planner to transfer only the entries needed for the latest document state — the best snapshot plus uncovered changes — skipping historical entries and deferring attachments. Ideal for mobile initial setup over bandwidth-constrained connections.
These invariants hold across all deployment topologies — client-server, P2P, relay chains, and mesh:
- Completeness — After a full sync cycle, the client has metadata awareness of every remote entry
- Idempotency — Every endpoint can be called repeatedly without side effects
- Order independence — Entries can arrive in any sequence; CRDTs handle convergence
- Deduplication — Identical entries from multiple sources stored once
For datasets beyond tens of thousands of entries, two techniques keep sync fast:
- Cursor scanning — Page through remote metadata incrementally instead of sending large ID lists. Request size stays constant regardless of total store size.
- Bloom filter summary — Download a compact probabilistic set representation to pre-filter IDs. Eliminates 90-99% of exact existence checks.
- CRDT snapshots — Periodic snapshots prevent performance degradation from replaying long document histories.
- Dense sync — Transfer only the latest snapshot and uncovered changes per document, skipping history and attachments. Learn more →
Every sync operation requires authentication via a challenge-response flow: the client signs a server-generated challenge with its Ed25519 key, and the server issues a short-lived JWT. Revocation is enforced at two points — during challenge generation and during token validation — so a revoked user is locked out immediately, even mid-session. No passwords or tokens are stored on the server.
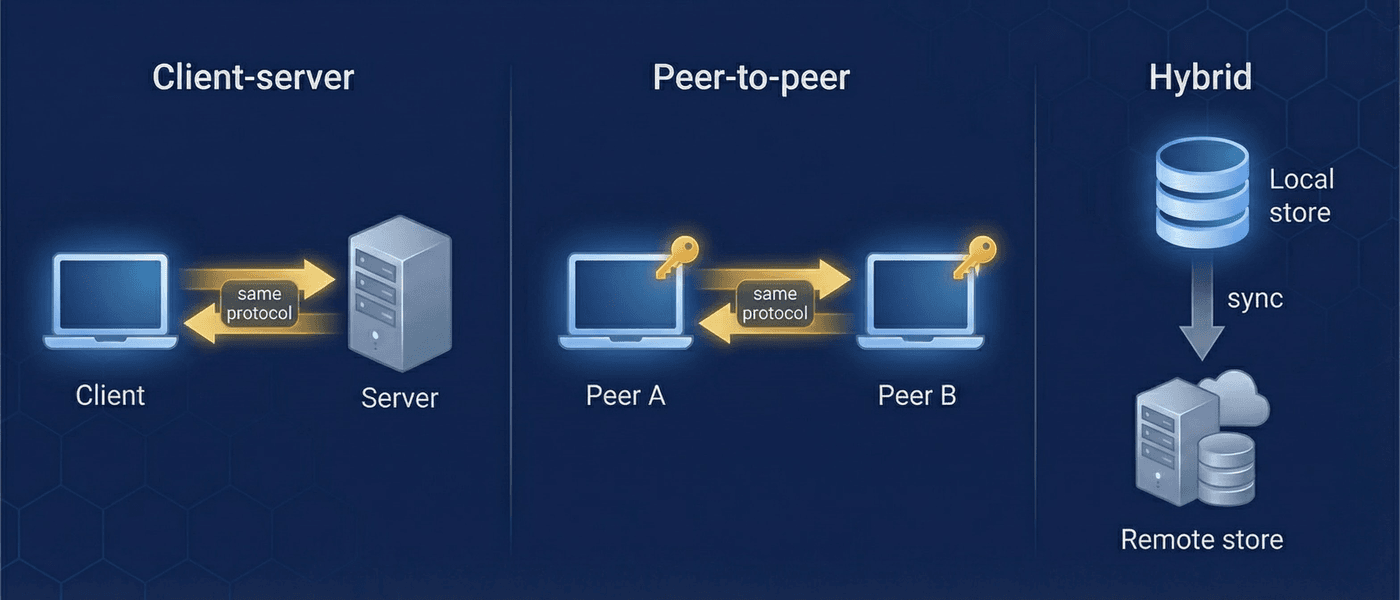
Same protocol, any network shape
Because sync operates on encrypted entries and uses the same ContentAddressedStore interface everywhere, any node can participate in sync without decrypting data. A relay server stores and forwards entries it cannot read. A regional cache serves entries to nearby clients without needing keys. The trust boundary is at the encryption key level, not the network topology level.
Standard deployment with a central server. Simplest to set up and operate. The server validates users via the directory, stores encrypted entries, and syncs with connected clients.
Two devices sync directly over LAN, WebRTC, or Bluetooth — no central server required. Each peer runs a lightweight server component wrapping its local store. Same pullChangesFrom/pushChangesTo API as client-server.
Data flows through nodes that cannot decrypt it. A hospital server syncs patient records between clinics without reading them. A passthrough node forwards requests to an origin server for edge caching or access boundaries.
| Topology | When to use | Infrastructure needed | Key benefit |
|---|---|---|---|
| Client-server | Default starting point; reliable always-on sync | One server + clients | Simplest deployment |
| Peer-to-peer | Same-network sync without server dependency | Clients only (LAN/WebRTC) | No server needed |
| Relay | Data distribution through untrusted nodes | Relay server (no keys needed) | Secure data distribution |
| Store chain | Edge caching, geographic distribution | Origin + edge nodes | Latency reduction |
| Mesh | Resilient multi-peer convergence | Multiple peers | No single point of failure |
| Hybrid | Server for reliability, P2P for speed | Server + direct peer links | Best of both worlds |
Crash safety and data integrity
MindooDB stores encrypted, content-addressed entries directly on the filesystem. This gives the store full control over commit ordering, crash recovery, and deduplication without depending on an embedded database engine like SQLite or LevelDB.
Every file write follows an atomic protocol: write to a temp file, fsync, atomic rename, fsync the parent directory. Readers never see partially written state. The commit order (payload first, then metadata, then index segment) ensures an entry only becomes discoverable after its payload is safely on disk.
- Crash between payload and metadata — Orphaned payload is harmless
- Crash between metadata and index — Entry is committed; index rebuilt on startup
- Crash during compaction — Stale index detected and rebuilt from authoritative entry files
On startup, the store attempts fast recovery first: load the metadata snapshot, replay incremental segments, and validate against authoritative entry files. If anything is stale or inconsistent, it falls back to a full rebuild from disk — transparently and without data loss.
- In-memory indexes — O(1) point lookups, binary-search cursor scans, document-scoped queries
- Segment compaction — Merges incremental metadata into fresh snapshots to keep startup fast
- Source of truth — Entry files on disk are always authoritative; index files are acceleration structures that can be safely deleted
For the full implementation deep-dive, see the on-disk store documentation.
Organizing data for growth
MindooDB's append-only architecture means data accumulates over time. Since every change is preserved for the audit trail, planning for data growth is important. The primary tool is database-level sharding: split data into separate databases by time period, category, access level, or geography. Each database syncs independently, so you control exactly what data flows where.
- Time-based — Yearly or monthly databases keep sync fast for active data while preserving history
- Category-based — Separate databases by document type, project, or business unit
- Access-based — Isolate data by security level so different teams sync different subsets
- Geographic — Databases per region for data residency requirements
Documents are encrypted at rest, so server-side queries are not possible. Instead, MindooDB provides client-side incremental indexing:
- Cursor-based processing —
iterateChangesSince(cursor)processes only documents that changed since the last run - Pluggable indexers — Feed changes to FlexSearch, Lunr, or any custom index
- Virtual Views — Spreadsheet-like categorized views with sorting and aggregation, spanning multiple databases or tenants
Tenant isolation and cross-tenant collaboration
Tenants are cryptographically isolated by default — each tenant has independent encryption keys, a separate user directory, and its own set of databases. Cross-tenant collaboration is possible by sharing specific databases or named encryption keys between tenants, while maintaining independent tenant administration.
- Each tenant has independent encryption keys — no shared secrets
- Separate user directories with independent admin keys
- Data isolated by default; sharing requires explicit key distribution
- Revoking a user in one tenant has no effect on other tenants
- Share specific databases between tenants using named keys
- Virtual Views can aggregate data across tenant boundaries
- Each tenant retains independent administration and revocation
- Useful for supply chains, partner organizations, and shared projects
What you should know before adopting
Every architecture involves tradeoffs. MindooDB's end-to-end encryption and append-only design provide strong security and auditability guarantees, but they come with constraints you should understand upfront.
Revoking a user blocks all future sync and rejects their future changes. However, previously synced data on their local device remains accessible — no system can guarantee deletion on a device that never reconnects. Mitigation: use named keys for sensitive documents (smaller blast radius), and rotate keys when users leave. Haven Enterprise adds an admin-signed remote device wipe to the same governance policies: the tenant is dropped from a stolen or departed device the next time it connects.
Because data is encrypted before leaving the client, the server cannot execute queries. All querying happens client-side through incremental indexing, Virtual Views, or pluggable search indexers. This is a deliberate tradeoff: confidentiality over server-side convenience.
Multiple keys per user (signing, encryption, named symmetric keys) require secure distribution. Mitigation: a single password unlocks all keys via KDF with different salts. The KeyBag provides unified key storage. The join request/response flow handles key exchange for new users. Haven Enterprise automates the ongoing work: admin-signed key distribution policies provision keys to users and groups — and revoke them again — wrapped per recipient, and every client reconciles its KeyBag on the next sync.
Data accumulates because the audit trail is preserved. Mitigation: database-level sharding controls growth per sync unit. CRDT snapshots reduce the replay cost. GDPR purge (purgeDocHistory) is available when regulatory deletion is required.
MindooDB Haven implements these primitives in a browser-based PWA: client-held keys, capability-based app sandboxing, flexible sync modes, and a real app platform. It is the fastest way to experience MindooDB end to end.